Advertisement

A survey on automatic image annotation
- Published: 09 June 2020
- Volume 50 , pages 3412–3428, ( 2020 )
Cite this article

- Yilu Chen 1 ,
- Xiaojun Zeng 1 ,
- Xing Chen 1 &
- Wenzhong Guo 1
1419 Accesses
17 Citations
Explore all metrics
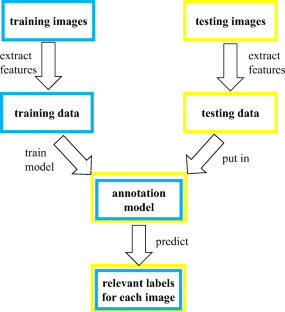
Automatic image annotation is a crucial area in computer vision, which plays a significant role in image retrieval, image description, and so on. Along with the internet technique developing, there are numerous images posted on the web, resulting in the fact that it is a challenge to annotate images only by humans. Hence, many computer vision researchers are interested in automatic image annotation and make a great effort in optimizing its performance. Automatic image annotation is a task that assigns several tags in a limited vocabulary to describe an image. There are many algorithms proposed to tackle this problem and all achieve great performance. In this paper, we review seven algorithms for automatic image annotation and evaluate these algorithms leveraging different image features, such as color histograms and Gist descriptor. Our goal is to provide insights into the automatic image annotation. A lot of comprehensive experiments, which are based on Corel5K, IAPR TC-12, and ESP Game datasets, are designed to compare the performance of these algorithms. We also compare the performance of traditional algorithms employing deep learning features. Considering that not all associated labels are annotated by human annotators, we leverage the DIA metrics on IAPR TC-12 and ESP Game datasets.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

Improving loss function for deep convolutional neural network applied in automatic image annotation

Automatic image annotation: the quirks and what works
Cnn-feature based automatic image annotation method.
http://cvit.iiit.ac.in/projects/imageAnnotation/
http://lear.inrialpes.fr/people/guillaumin/code.php#tagprop
http://ranger.uta.edu/~huang/codes/annotation_corel.zip
http://www.cse.wustl.edu/~mchen/
https://sites.google.com/site/baoyuanwu2015/demo-code-MLML-MG-ICCV2015.zip?attredirects=0&d=1
https://github.com/wubaoyuan/DIA
Adeniyi DA, Wei Z, Yongquan Y (2016) Automated web usage data mining and recommendation system using k-nearest neighbor (knn) classification method. Appl Comput Inform 12(1):S221083271400026X
Article Google Scholar
Akata Z, Reed S, Walter D, Lee H, Schiele B (2015) Evaluation of output embeddings for fine-grained image classification. In: Proceedings of the conference on computer vision and pattern recognition. IEEE, pp 2927–2936
Bannour H, Hudelot C (2014) Building and using fuzzy multimedia ontologies for semantic image annotation. Multimed Tools Appl 72(3):2107–2141
Bertsimas D, Nohadani O (2019) Robust maximum likelihood estimation. INFORMS J Comput 31 (3):445–458
Article MathSciNet Google Scholar
Boyd S, Parikh N, Chu E, Peleato B, Eckstein J, et al. (2011) Distributed optimization and statistical learning via the alternating direction method of multipliers. Found Trends®; Mach Learn 3(1):1–122
MATH Google Scholar
Brinker K, Hüllermeier E (2007) Case-based multilabel ranking. In: Proceedings of the international joint conference on artificial intelligence
Castellano G, Fanelli AM, Sforza G, Torsello MA (2016) Shape annotation for intelligent image retrieval. Appl Intell 44(1):179–195
Chatfield K, Simonyan K, Vedaldi A, Zisserman A (2014) Return of the devil in the details: delving deep into convolutional nets. In: Proceedings of British machine vision conference
Chen M, Xu Z, Weinberger K, Sha F (2012) Marginalized denoising autoencoders for domain adaptation. In: Proceedings of the international conference on machine learning
Chen M, Zheng A, Weinberger K (2013) Fast image tagging. In: Proceedings of the international conference on machine learning, pp 1274–1282
Chen X, Gupta A (2015) Webly supervised learning of convolutional networks. In: Proceedings of the international conference on computer vision. IEEE, pp 1431–1439
Cox DR, Isham V (2018) Point processes. Routledge
Divvala SK, Farhadi A, Guestrin C (2014) Learning everything about anything: webly-supervised visual concept learning. In: Proceedings of the conference on computer vision and pattern recognition. IEEE, pp 3270–3277
Duygulu P, Barnard K, de Freitas JF, Forsyth DA (2002) Object recognition as machine translation: learning a lexicon for a fixed image vocabulary. In: Proceedings of the European conference on computer vision. Springer, pp 97–112
Feng Z, Feng S, Jin R, Jain AK (2014) Image tag completion by noisy matrix recovery. In: Proceedings of the European conference on computer vision. Springer, pp 424–438
Frank A, Fabregat-Traver D, Bientinesi P (2016) Large-scale linear regression: development of high-performance routines. Appl Math Comput 275:411–421
MathSciNet MATH Google Scholar
Gong C, Tao D, Liu W, Liu L, Yang J (2017) Label propagation via teaching-to-learn and learning-to-teach. IEEE Trans Neural Netw Learn Syst 28(6):1452–1465
Gong C, Tao D, Yang J, Liu W (2016) Teaching-to-learn and learning-to-teach for multi-label propagation. In: Proceedings of association for the advancement of artificial intelligence, pp 1610–1616
Grubinger M, Clough P, Müller H, Deselaers T (2006) The iapr tc-12 benchmark: a new evaluation resource for visual information systems. In: Proceedings of int. workshop OntoImage, vol 5
Guillaumin M, Mensink T, Verbeek J, Schmid C (2009) Tagprop: discriminative metric learning in nearest neighbor models for image auto-annotation. In: Proceedings of the international conference on computer vision. IEEE, pp 309–316
Guo H, Zheng K, Fan X, Yu H, Wang S (2019) Visual attention consistency under image transforms for multi-label image classification. In: Proceedings of the conference on computer vision and pattern recognition, pp 729–739
Haque R, Penkale S, Way A (2018) Termfinder: log-likelihood comparison and phrase-based statistical machine translation models for bilingual terminology extraction. Lang Resour Eval 52(2):365–400
Hsu DJ, Kakade SM, Langford J, Zhang T (2009) Multi-label prediction via compressed sensing. In: Proceedings of the conference on neural information processing systems, pp 772–780
Jiang X, Zeng W, So H, Zoubir AM, Kirubarajan T (2016) Beamforming via nonconvex linear regression. IEEE Trans Signal Process 64(7):1714–1728
Kalayeh MM, Idrees H, Shah M (2014) Nmf-knn: image annotation using weighted multi-view non-negative matrix factorization. In: Proceedings of the conference on computer vision and pattern recognition, pp 184–191
Kapoor A, Viswanathan R, Jain P (2012) Multilabel classification using Bayesian compressed sensing. In: Advances in neural information processing systems, pp 2645–2653
Ke X, Li S, Chen G (2013) Real web community based automatic image annotation. Comput Electr Eng 39(3):945–956
Ke X, Zou J, Niu Y (2019) End-to-end automatic image annotation based on deep cnn and multi-label data augmentation. IEEE Transactions on Multimedia
Keller JM, Gray MR, Givens JA (2012) A fuzzy k-nearest neighbor algorithm. IEEE Trans Syst Man Cybern SMC-15(4):580–585
Knerr B, Holzer M, Angerer C, Rupp M (2010) Slot-wise maximum likelihood estimation of the tag population size in FSA protocols. IEEE Trans Commun 58(2):578–585
Ko V, Hjort NL (2019) Model robust inference with two-stage maximum likelihood estimation for copulas. J Multivar Anal 171:362–381
Kulesza A, Taskar B, et al. (2012) Determinantal point processes for machine learning. Found Trends®; Mach Learn 5(2–3):123–286
Li Y, Yang H (2014) Efficiency of a stochastic restricted two-parameter estimator in linear regression. Appl Math Comput 249:371–381
Liu W, He J, Chang SF (2010) Large graph construction for scalable semi-supervised learning. In: Proceedings of the international conference on machine learning, pp 679–686
Liu Y, Ma Z, Fang Y (2017) Adaptive density peak clustering based on k-nearest neighbors with aggregating strategy. Knowl-Based Syst 133:S095070511730326X
Google Scholar
Luo F, Guo W, Yu Y, Chen G (2017) A multi-label classification algorithm based on kernel extreme learning machine. Neurocomputing 260:313–320
Makadia A, Pavlovic V, Kumar S (2008) A new baseline for image annotation. In: Proceedings of the European conference on computer vision. Springer, pp 316–329
Moran S, Lavrenko V (2014) A sparse kernel relevance model for automatic image annotation. Int J Multimed Inform Retriev 3(4):209–229
Oliva A, Torralba A (2001) Modeling the shape of the scene: a holistic representation of the spatial envelope. Int J Comput Vis 42(3):145–175
Pennington J, Socher R, Manning C (2014) Glove: global vectors for word representation. In: Proceedings of the conference on empirical methods in natural language processing, pp 1532–1543
Rousu J, Saunders C, Szedmák S, Shawe-Taylor J (2006) Kernel-based learning of hierarchical multilabel classification models. J Mach Learn Res 7:1601–1626
Sim S, Bae H, Choi Y (2019) Likelihood-based multiple imputation by event chain methodology for repair of imperfect event logs with missing data. In: Proceedings of the international conference on process mining, pp 9–16
Spyromitros E, Tsoumakas G, Vlahavas I (2008) An empirical study of lazy multilabel classification algorithms. In: Proceedings of conference on artificial intelligence: theories, models and applications
Tousch A, Herbin S, Audibert J (2012) Semantic hierarchies for image annotation: a survey. Pattern Recogn 45(1):333–345
Verma Y, Jawahar C (2012) Image annotation using metric learning in semantic neighbourhoods. In: Proceedings of the European conference on computer vision. Springer, pp 836–849
Von Ahn L, Dabbish L (2004) Labeling images with a computer game. In: Proceedings of the SIGCHI conference on human factors in computing systems. ACM, pp 319–326
Wang C, Yan S, Zhang L, Zhang H (2009) Multi-label sparse coding for automatic image annotation. In: Proceedings of the conference on computer vision and pattern recognition
Wang J, Yang Y, Mao J, Huang Z, Huang C, Xu W (2016) Cnn-rnn: a unified framework for multi-label image classification. In: Proceedings of the conference on computer vision and pattern recognition, pp 2285–2294
Wang Z, Gong G (2018) Discrete fourier transform of boolean functions over the complex field and its applications. IEEE Trans Inf Theory 64(4):3000–3009
Wu B, Jia F, Liu W, Ghanem B (2017) Diverse image annotation. In: Proceedings of the conference on computer vision and pattern recognition. IEEE
Wu B, Lyu S, Ghanem B (2015) Ml-mg: multi-label learning with missing labels using a mixed graph. In: Proceedings of the international conference on computer vision. IEEE, pp 4157–4165
Xuan J, Lu J, Zhang G, Xu RYD, Luo X (2017) A bayesian nonparametric model for multi-label learning. Mach Learn 106(11):1787–1815
Yu G, Zhu H, Domeniconi C (2015) Predicting protein functions using incomplete hierarchical labels. BMC Bioinform 16:1:1– 1:12
Yu Y, Sun Z (2017) Sparse coding extreme learning machine for classification. Neurocomputing 261:50–56
Zhang C, Jing L, Qi T, Xu C (2014) Image classification by non-negative sparse coding, low-rank and sparse decomposition. In: Proceedings of the conference on computer vision and pattern recognition
Zhang H, Wu W, Wang D (2018) Multi-instance multi-label learning of natural scene images: via sparse coding and multi-layer neural network. IET Comput Vis 12(3):305–311
Zhang ML, Zhou ZH (2007) Ml-knn: a lazy learning approach to multi-label learning. Pattern Recogn 40 (7):2038–2048
Zhang S, Huang J, Huang Y, Yu Y, Li H, Metaxas DN (2010) Automatic image annotation using group sparsity. In: Proceedings of the conference on computer vision and pattern recognition. IEEE, pp 3312–3319
Zhang T, Ghanem B, Liu S, Ahuja N (2012) Low-rank sparse learning for robust visual tracking. In: Proceedings of the European conference on computer vision. Springer, pp 470– 484
Zhang T, Ghanem B, Liu S, Xu C, Ahuja N (2013) Low-rank sparse coding for image classification. In: Proceedings of the international conference on computer vision, pp 281–288
Zhang T, Ghanem B, Liu S, Xu C, Ahuja N (2014) Low-rank sparse coding for image classification. In: Proceedings of the international conference on computer vision
Zhang T, Liu S, Ahuja N, Yang MH, Ghanem B (2015) Robust visual tracking via consistent low-rank sparse learning. Int J Comput Vis 111(2):171–190
Zhang X, Li W, Nguyen V, Zhuang F, Xiong H, Lu S (2018) Label-sensitive task grouping by Bayesian nonparametric approach for multi-task multi-label learning. In: Proceedings of the international joint conference on artificial intelligence Sweden, pp 3125–3131
Zhe X, Ou-Yang L, Chen S, Yan H (2019) Semantic hierarchy preserving deep hashing for large-scale image retrieval. arXiv: https://arxiv.org/abs/1901.11259
Zhong S, Chen T, He F, Niu Y (2014) Fast gaussian kernel learning for classification tasks based on specially structured global optimization. Neural Netw 57:51–62
Zhu G, Yan S, Ma Y (2010) Image tag refinement towards low-rank, content-tag prior and error sparsity. In: Proceedings of the international conference on multimedia. ACM, pp 461–470
Download references
Acknowledgements
This work was supported in part by Guiding Project of Fujian Province under Grant No. 2018H0017 and the Talent Program of Fujian Province for Distinguished Young Scholars in Higher Education.
Author information
Authors and affiliations.
The College of Mathematics and Computer Science, Fuzhou University, Fujian, China
Yilu Chen, Xiaojun Zeng, Xing Chen & Wenzhong Guo
You can also search for this author in PubMed Google Scholar
Corresponding authors
Correspondence to Xing Chen or Wenzhong Guo .
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Chen, Y., Zeng, X., Chen, X. et al. A survey on automatic image annotation. Appl Intell 50 , 3412–3428 (2020). https://doi.org/10.1007/s10489-020-01696-2
Download citation
Published : 09 June 2020
Issue Date : October 2020
DOI : https://doi.org/10.1007/s10489-020-01696-2
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Computer vision
- Image annotation
- Tag assignment
- Image retrieval
- Find a journal
- Publish with us
- Track your research
Subscribe to the PwC Newsletter
Join the community, edit social preview.

Add a new code entry for this paper
Remove a code repository from this paper, mark the official implementation from paper authors, add a new evaluation result row.
- CONTENT-BASED IMAGE RETRIEVAL
- IMAGE RETRIEVAL
Remove a task

Add a method
Remove a method, edit datasets, an effective automatic image annotation model via attention model and data equilibrium.
26 Jan 2020 · Amir Vatani , Milad Taleby Ahvanooey , Mostafa Rahimi · Edit social preview
Nowadays, a huge number of images are available. However, retrieving a required image for an ordinary user is a challenging task in computer vision systems. During the past two decades, many types of research have been introduced to improve the performance of the automatic annotation of images, which are traditionally focused on content-based image retrieval. Although, recent research demonstrates that there is a semantic gap between content-based image retrieval and image semantics understandable by humans. As a result, existing research in this area has caused to bridge the semantic gap between low-level image features and high-level semantics. The conventional method of bridging the semantic gap is through the automatic image annotation (AIA) that extracts semantic features using machine learning techniques. In this paper, we propose a novel AIA model based on the deep learning feature extraction method. The proposed model has three phases, including a feature extractor, a tag generator, and an image annotator. First, the proposed model extracts automatically the high and low-level features based on dual-tree continues wavelet transform (DT-CWT), singular value decomposition, distribution of color ton, and the deep neural network. Moreover, the tag generator balances the dictionary of the annotated keywords by a new log-entropy auto-encoder (LEAE) and then describes these keywords by word embedding. Finally, the annotator works based on the long-short-term memory (LSTM) network in order to obtain the importance degree of specific features of the image. The experiments conducted on two benchmark datasets confirm that the superiority of the proposed model compared to the previous models in terms of performance criteria.
Code Edit Add Remove Mark official
Tasks edit add remove, datasets edit, results from the paper edit add remove, methods edit add remove.
Automatic Image Annotation and Object Detection
Tang, Jiayu (2008) Automatic Image Annotation and Object Detection. University of Southampton , ECS , Doctoral Thesis .
We live in the midst of the information era, during which organising and indexing information more effectively is a matter of essential importance. With the fast development of digital imagery, how to search images - a rich form of information - more efficiently by their content has become one of the biggest challenges. Content-based image retrieval (CBIR) has been the traditional and dominant technique for searching images for decades. However, not until recently have researchers started to realise some vital problems existing in CBIR systems. One of the most important is perhaps what people call the semantic gap , which refers to the gap between the information that can be extracted from images and the interpretation of the images for humans. As an attempt to bridge the semantic gap, automatic image annotation has been gaining more and more attentions in recent years. This thesis aims to explore a number of different approaches to automatic image annotation and some related issues. It begins with an introduction into different techniques for image description, which forms the foundation of the research on image auto-annotation. The thesis then goes on to give an in-depth examination of some of the quality issues of the data-set used for evaluating auto-annotation systems. A series of approaches to auto-annotation are presented in the follow-up chapters. Firstly, we describe an approach that incorporates the salient based image representation into a statistical model for better annotation performance. Secondly, we explore the use of non-negative matrix factorisation (NMF), a matrix decomposition technique, for two tasks; object class detection and automatic annotation of images. The results imply that NMF is a promising sub-space technique for these purposes. Finally, we propose a model named the image based feature space (IBFS) model for linking image regions and keywords, and for image auto-annotation. Both image regions and keywords are mapped into the same space in which their relationships can be measured. The idea of multiple segmentations is then implemented in the model, and better results are achieved than using a single segmentation.
More information
Identifiers, catalogue record, export record, share this record, contributors, download statistics.
Downloads from ePrints over the past year. Other digital versions may also be available to download e.g. from the publisher's website.
View more statistics
Contact ePrints Soton: [email protected]
ePrints Soton supports OAI 2.0 with a base URL of http://eprints.soton.ac.uk/cgi/oai2
This repository has been built using EPrints software , developed at the University of Southampton, but available to everyone to use.
We use cookies to ensure that we give you the best experience on our website. If you continue without changing your settings, we will assume that you are happy to receive cookies on the University of Southampton website.
Help | Advanced Search
Computer Science > Computation and Language
Title: automated annotation with generative ai requires validation.
Abstract: Generative large language models (LLMs) can be a powerful tool for augmenting text annotation procedures, but their performance varies across annotation tasks due to prompt quality, text data idiosyncrasies, and conceptual difficulty. Because these challenges will persist even as LLM technology improves, we argue that any automated annotation process using an LLM must validate the LLM's performance against labels generated by humans. To this end, we outline a workflow to harness the annotation potential of LLMs in a principled, efficient way. Using GPT-4, we validate this approach by replicating 27 annotation tasks across 11 datasets from recent social science articles in high-impact journals. We find that LLM performance for text annotation is promising but highly contingent on both the dataset and the type of annotation task, which reinforces the necessity to validate on a task-by-task basis. We make available easy-to-use software designed to implement our workflow and streamline the deployment of LLMs for automated annotation.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
CycleFusion: Automatic Annotation and Graph-to-Graph Transaction Based Cycle-Consistent Adversarial Network for Infrared and Visible Image Fusion
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
The Orchive: A system for semi-automatic annotation and analysis of a large collection of bioacoustic recordings
Journal title, journal issn, volume title, description, collections.
Human and automatic annotation of discourse relations for Arabic
--> Alsaif, Amal (2012) Human and automatic annotation of discourse relations for Arabic. PhD thesis, University of Leeds.
This thesis describes the first, inter-disciplinary, study on human and automatic discourse annotation for explicit discourse connectives in Modern Standard Arabic (MSA). Discourse connectives are used in language to link discourse segments (arguments) by indicating so-called discourse relations. Automating the process of identifying the discourse connectives, their relations and their arguments is an essential basis for discourse processing studies and applications. This study presents several resources for Arabic discourse processing in addition to the first machine learning algorithms for identifying explicit discourse connectives and relations automatically. First, we have collected a large list of discourse connectives frequently used in MSA. This collection is used to develop the READ tool: the first annotation tool to fit the characteristics of Arabic, so that Arabic texts can be annotated by humans for discourse structure. Second, our analysis of Arabic discourse connectives leads to formalize an annotation scheme for connectives in context, based on a popular discourse annotation project for English, the PDTB project. Third, we used this scheme to create the first discourse corpus for Arabic, the Leeds Arabic Discourse Treebank (LADTB v.1). The LADTB extends the syntactic annotation of the Arabic Treebank Part1 to incorporate the discourse layer, by annotating all explicit connectives as well as associated relations and arguments. We show that the LADTB annotation is reliable and produce a gold standard for future work. Fourth, we develop the first automatic identification models for Arabic discourse connectives and relations, using the LADTB for training and testing. Our connective recogniser achieves almost human performance. Our algorithm for recognizing discourse relations performs significantly better than a baseline based on the connective surface string alone and therefore reduces the ambiguity in explicit connective interpretation. At the end of the thesis, we highlight research trends for future work that can benefit from our resources and algorithms on discourse processing for Arabic.
--> Amal_PhD_thesis_November --> -->
Filename: Amal_PhD_thesis_November.pdf

Embargo Date:
![[img]](https://etheses.whiterose.ac.uk/style/images/fileicons/text.png "automatic annotation thesis")
You do not need to contact us to get a copy of this thesis. Please use the 'Download' link(s) above to get a copy. You can contact us about this thesis . If you need to make a general enquiry, please see the Contact us page.

COMMENTS
Focusing on the agriculture field, this study implements automatic image annotation, namely, a repetitive annotation task technique, to classify the ripeness of oil palm fruit and recognize a ...
Automatic image annotation is one of the fundamental problems in computer vision and machine learning. Given an image, here the goal is to predict a set of textual labels that describe the semantics of that image. During the last decade, a large number of image annotation techniques have been proposed that have been shown to achieve encouraging results on various annotation datasets. However ...
It will also describe the CARRADA dataset, composed of synchronised camera and RADAR data with a semi-automatic annotation method. This thesis then present a proposed set of deep learning architectures with their associated loss functions for RADAR semantic segmentation. It also introduces a method to open up research into the fusion of LiDAR ...
Recently, much attention has been given to image annotation due to the massive increase in image data volume. One of the image retrieval methods which guarantees the retrieval of images in the same way as texts are automatic image annotation (AIA). Consequently, numerous studies have been conducted on AIA, particularly on the classification-based and probabilistic modeling techniques. Several ...
Automatic image annotation (AIA) can automatically arrange the annotation words (also called labels) ... Nakayama H (2011) Linear distance metric learning for large-scale generic image recognition, PhD thesis, The University of Tokyo. Nello C, John ST (2000) An introduction to support vector machines and other kernel-based learning methods ...
Automatic image annotation is a crucial area in computer vision, which plays a significant role in image retrieval, image description, and so on. Along with the internet technique developing, there are numerous images posted on the web, resulting in the fact that it is a challenge to annotate images only by humans. Hence, many computer vision researchers are interested in automatic image ...
ucts within an image can be predicted with high accuracy, the annotation could be done fully automatically. The locations of products within images are also of interest since they enable the placement of links to products in user-friendly spots. 1.3 Problem Formulation This thesis explores different approaches to improve the performance of a model
thesis, Univers ity of S outhampton, United K ingdom, May 2008. [14] ... There are many approaches for automatic annotation in digital images. Nowadays digital photography is a common technology ...
Automatic image annotation. is one of the fundamental problems that symbolizes the inter-play between visual and. textual data. It aims at associating a set of discrete labels with a given image ...
The conventional method of bridging the semantic gap is through the automatic image annotation (AIA) that extracts semantic features using machine learning techniques. In this paper, we propose a novel AIA model based on the deep learning feature extraction method. The proposed model has three phases, including a feature extractor, a tag ...
This thesis aims to explore a number of different approaches to automatic image annotation and some related issues. It begins with an introduction into different techniques for image description, which forms the foundation of the research on image auto-annotation.
Generative large language models (LLMs) can be a powerful tool for augmenting text annotation procedures, but their performance varies across annotation tasks due to prompt quality, text data idiosyncrasies, and conceptual difficulty. Because these challenges will persist even as LLM technology improves, we argue that any automated annotation process using an LLM must validate the LLM's ...
The project aims to generate a tool to automatically annotate 3D point clouds from labelled 2D images. In order for this to be fullfiled, we establish some requirements and specifications. The system must be able to process multiple input data, we expect to have hundreds of inputs, scalability is a must.
In the domain of infrared and visible image fusion, the objective is to extract prominent targets and intricate textures from source images to produce a fused image with heightened visual impact. While deep learning-based fusion methods offer the advantage of end-to-end fusion, their design complexities are compounded by the absence of ground truth. To address this challenge, we developed an ...
The current study is the first fusing task-specific neural networks to develop a fully automated, multi-stage, deep-learning-based framework, entitled ORCA-SLANG, performing semi-supervised call type identification in one of the largest animal-specific bioacoustic archives - the Orchive.
The criteria for evaluating annotation systems are also presented in this study. In conclusion, a synthesis of methods of automatic image annotation were shown by presenting the pros and cons of each.
In this thesis, a system is presented that assists researchers to listen to, view, anno- tate and run advanced audio feature extraction and machine learning algorithms on these audio recordings. This system is designed to scale to petabyte size. ... The Orchive: A system for semi-automatic annotation and analysis of a large collection of ...
Automatic Annotation of Similes in Literary Texts 2 Suzanne Mpouli - November 2016 I am also indebted to all my friends who inquired about the progress of my thesis and patiently listened to me each time I needed it. I would specially like to express my deepest gratitude to Albert and Christelle who took time to read parts of my thesis.
manual annotation, and the accuracy regarding the automatic annotation. The Thesis presents two experiments followed for the evaluation of the annotation process: the first experiment consists on testing how the content-based similarity can propagate labels. Using a collection of of ∼5500 songs, we show that with a collection
vide ML-assisted annotation suggestions as well as manual correction of image annotations. 1.3Aim This thesis aims to integrate an efficient semi-automatic image annotation tool within the Ngulia system. The annotated images should be integrated with exist-ing training data of the model, thus allowing iterative learning. It will be inves-
This thesis describes the first, inter-disciplinary, study on human and automatic discourse annotation for explicit discourse connectives in Modern Standard Arabic (MSA). Discourse connectives are used in language to link discourse segments (arguments) by indicating so-called discourse relations. Automating the process of identifying the discourse connectives, their relations and their ...
The work of this thesis is in three folds: data annotation, neural network training, and model application. ... the results of the automatic analysis are integrated in the user interface ...
Thesis document. This page links to the online version of the PhD dissertation: Automatic Annotation of Musical Audio for Interactive Applications, Paul M. Brossier Centre for Digital Music, Queen Mary University of London under the Direction of Dr. Mark Plumbley and Prof. Mark Sandler External Examiners: ...
Amongst these annotation techniques, we concentrate on low and mid-level tasks such as onset detection, pitch tracking, tempo extraction and note modelling. We present a framework to extract these annotations and evaluate the performances of different algorithms. The first task is to detect onsets and offsets in audio streams within short la ...